@Transient 필드가 10개가 되었을 때 -- 엔티티에서 DTO로 분리한 과정
처음에는 @Transient가 편했다#
프로젝트 초기에는 엔티티에 @Transient를 붙여서 DB에 안 들어가는 임시 필드를 관리했습니다.
@Entity
public class Building {
@Id
private Long id;
private String name;
private String address;
@Transient
private List<String> availableLectureRooms;
}필드 하나 추가하고 @Transient 붙이면 끝이니까, 빠르게 기능을 만들어야 하는 초기에는 이게 맞는 선택이었습니다. DTO 클래스를 따로 만들고 변환 로직 짜는 건 오버헤드였습니다.
문제는 기능이 늘어나면서 생겼습니다.
엔티티가 비대해진 과정#
처음에 @Transient 필드가 1-2개였을 때는 괜찮았습니다. 그런데 요구사항이 추가되면서 하나씩 늘어나기 시작했습니다.
- API 응답에만 필요한 계산 값 (
@Transient) - 특정 화면에서만 쓰는 부가 정보 (
@Transient) - JSON 직렬화 제어 (
@JsonIgnore,@JsonProperty) - 조건부 컬럼 제어 (
@Column(insertable = false, updatable = false))
어느 순간 엔티티를 열었는데, 필드가 20개 넘어가 있었고 그중 DB 컬럼이 아닌 필드가 절반 가까이 됐습니다. 엔티티만 보고 어떤 필드가 실제 테이블에 있는 컬럼이고 어떤 게 임시인지 구분이 안 됐습니다.
이게 왜 고통스러운지는, 다른 사람이 이 엔티티를 처음 볼 때 드러납니다. DB 스키마를 확인하려고 엔티티를 열었는데 @Transient, @JsonIgnore, @JsonProperty가 섞여 있으면 "이 필드가 실제 컬럼인가?"를 하나씩 어노테이션을 확인해야 합니다.
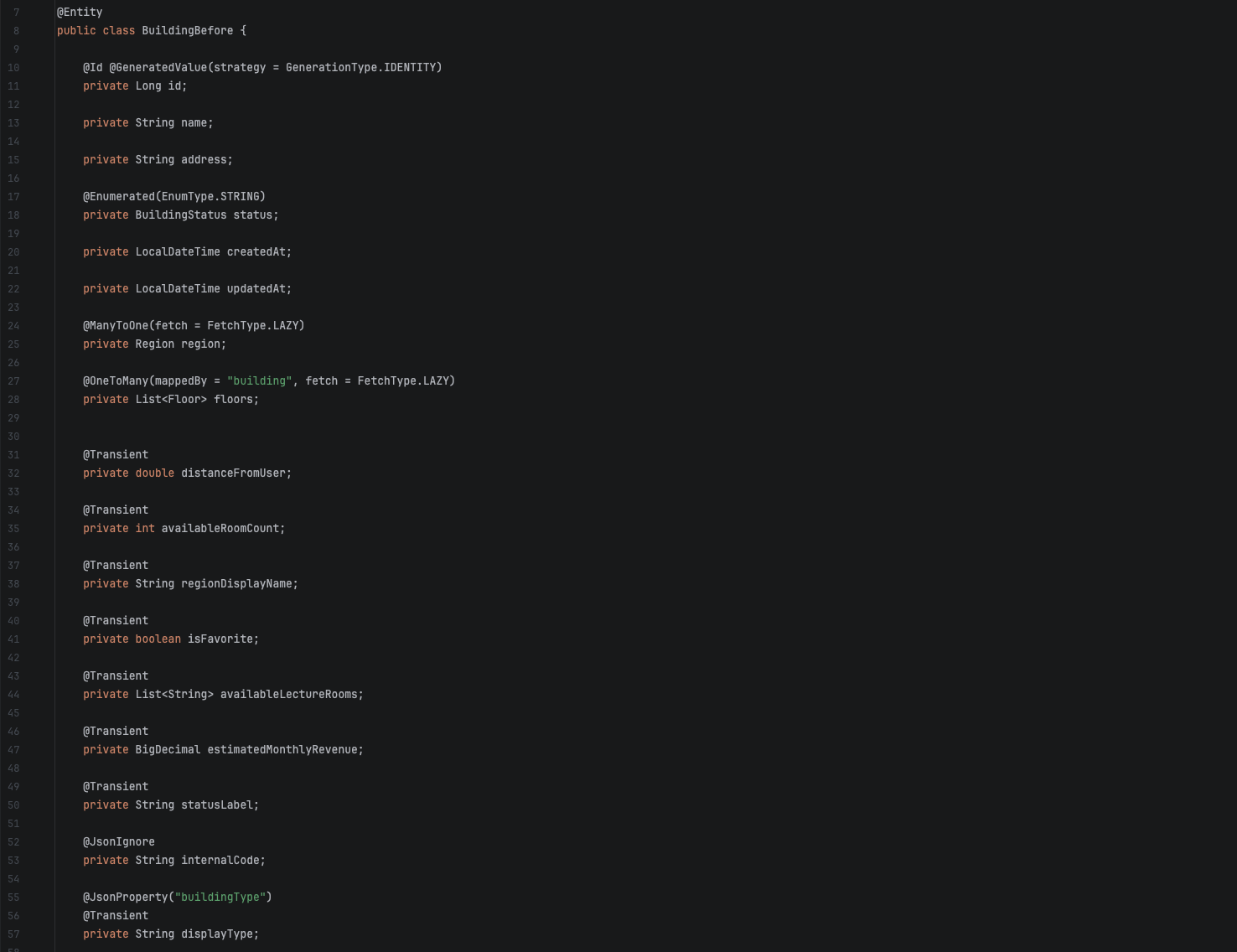
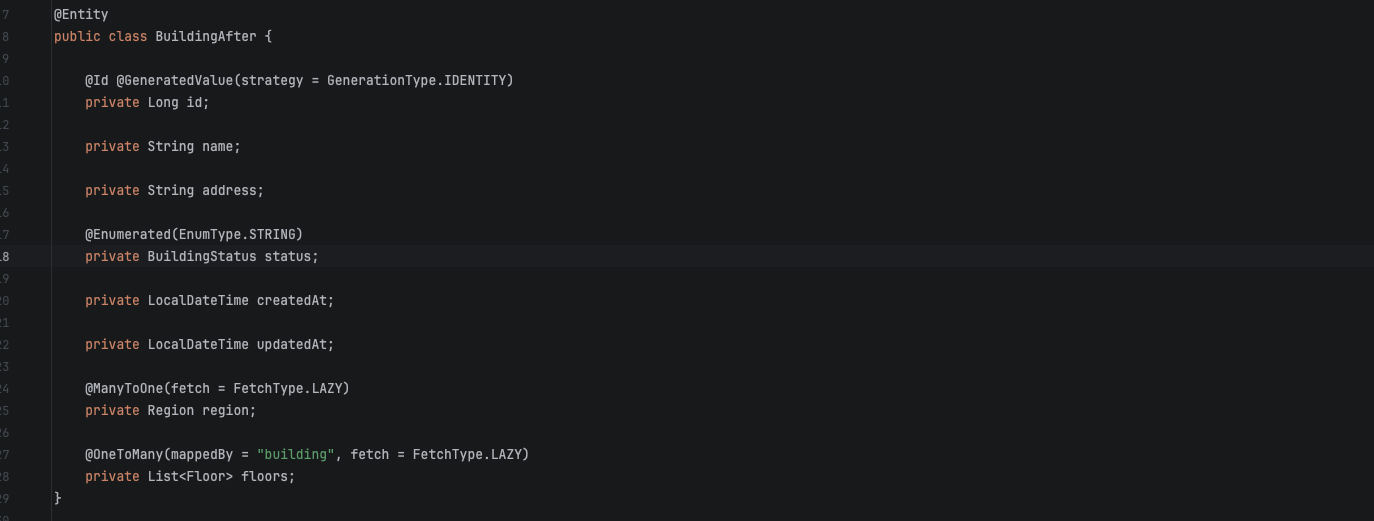
DTO 분리 후에는 엔티티에 DB 컬럼만 남습니다. 열었을 때 의도가 바로 보입니다.
이름만 같고 다른 세 가지 @Transient#
분리를 결심하기 전에, 직렬화에서 혼란이 먼저 터졌습니다.
@Transient라는 이름이 붙은 게 세 가지입니다. 각각 동작이 다릅니다.
@Entity
public class Building {
@Id
private Long id;
private String name;
// (1) javax.persistence.Transient -- DB 제외, JSON에는 나감
@javax.persistence.Transient
private double distanceFromUser;
// (2) java.beans.Transient -- JavaBeans 스펙. Jackson 2.6+에서 직렬화 제외
@java.beans.Transient
public String getInternalCode() {
return "INTERNAL-" + id;
}
// (3) transient 키워드 -- DB 제외, Jackson 기본 설정에서도 제외
private transient String tempCalculation;
}| 종류 | DB 저장 | Jackson 직렬화 |
|---|---|---|
javax.persistence.@Transient | X | O (노출됨) |
java.beans.@Transient | 상황에 따라 | X (Jackson 2.6+) |
transient 키워드 | X | X (제외됨) |
@JsonIgnore | 무관 | X |
실무에서 겪은 함정이 이거였습니다. @Transient(javax.persistence)를 붙였으니 API 응답에 안 나올 거라 생각했는데, Jackson은 이 어노테이션을 모르기 때문에 distanceFromUser가 그대로 JSON에 노출됐습니다.
@RestController
public class BuildingController {
@GetMapping("/buildings/{id}")
public Building getBuilding(@PathVariable Long id) {
Building b = buildingRepository.findById(id).orElseThrow();
b.setDistanceFromUser(3.5); // 임시 계산값
return b; // JSON에 distanceFromUser: 3.5 가 그대로 나감
}
}이걸 막으려고 @JsonIgnore를 붙이면, 이번에는 엔티티가 Jackson에 의존하게 됩니다. 도메인 객체가 프레젠테이션 레이어의 관심사를 알아야 하는 구조가 되는 겁니다.
엔티티 직접 반환의 두 번째 함정: Hibernate 프록시#
@Transient 문제를 넘어서, 엔티티를 컨트롤러에서 직접 반환하면 Hibernate 프록시 관련 문제도 생깁니다.
LazyInitializationException#
@Entity
public class Building {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
private Region region; // 프록시 상태로 로딩
}
@GetMapping("/buildings/{id}")
public Building getBuilding(@PathVariable Long id) {
Building b = buildingRepository.findById(id).orElseThrow();
return b;
// Jackson이 b.getRegion()을 호출하는 순간:
// org.hibernate.LazyInitializationException:
// could not initialize proxy [Region#1] - no Session
}@Transactional 없이 호출하면, Jackson 직렬화 시점에 이미 영속성 컨텍스트가 닫혀 있어서 LazyInitializationException이 터집니다.
OSIV가 켜져있을 때의 프록시 직렬화#
spring.jpa.open-in-view=true(Spring Boot 기본값)이면 세션은 열려있지만, Jackson이 프록시 객체 내부를 직렬화하면서 다른 문제가 생깁니다.
com.fasterxml.jackson.databind.exc.InvalidDefinitionException:
No serializer found for class
org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor
jackson-datatype-hibernate5 모듈을 등록하면 프록시를 null이나 ID로 변환해주긴 하지만, 이건 문제를 숨기는 것이지 해결하는 게 아닙니다.
N+1 문제#
Jackson이 엔티티를 순회하면서 getter를 호출하고, 그 과정에서 lazy 컬렉션이 초기화됩니다.
@Entity
public class Building {
@OneToMany(mappedBy = "building", fetch = FetchType.LAZY)
private List<Floor> floors;
}
@GetMapping("/buildings")
public List<Building> list() {
List<Building> buildings = buildingRepository.findAll();
return buildings;
// Jackson이 각 building.getFloors() 호출
// SELECT * FROM building -- 1번
// SELECT * FROM floor WHERE building_id = 1 -- N번
// SELECT * FROM floor WHERE building_id = 2
// ...
}이 세 가지 문제의 공통 원인은 하나입니다. 엔티티를 직접 API 응답으로 내보내고 있다는 것.
DTO로 분리#
전환의 핵심은 간단합니다. 엔티티는 DB 매핑만, 응답 형태는 DTO에서 결정.
// 엔티티 -- DB 매핑만 담당
@Entity
public class Building {
@Id
private Long id;
private String name;
private String address;
@ManyToOne(fetch = FetchType.LAZY)
private Region region;
@OneToMany(mappedBy = "building", fetch = FetchType.LAZY)
private List<Floor> floors;
}
// 응답 DTO -- 프레젠테이션 관심사 담당
public record BuildingResponseDto(
Long id,
String name,
String address,
String regionName,
List<String> availableLectureRooms
) {
public static BuildingResponseDto from(Building building, List<String> rooms) {
return new BuildingResponseDto(
building.getId(),
building.getName(),
building.getAddress(),
building.getRegion().getName(),
rooms
);
}
}availableLectureRooms는 더 이상 엔티티에 없습니다. @JsonIgnore, @JsonProperty 같은 Jackson 어노테이션도 전부 DTO로 옮겼습니다. 엔티티에서 Jackson 의존성이 완전히 사라졌습니다.
DTO를 만드는 여러 가지 방법#
1. 정적 팩토리 메서드#
public record BuildingResponseDto(Long id, String name, String regionName) {
public static BuildingResponseDto from(Building building) {
return new BuildingResponseDto(
building.getId(),
building.getName(),
building.getRegion().getName()
);
}
}간단한 경우에 가장 좋습니다. 필드가 명시적으로 보이니까 어떤 값이 어디서 오는지 추적하기 쉽습니다.
2. JPQL Constructor Expression#
@Query("SELECT new com.example.dto.BuildingListDto(b.id, b.name, b.region.name) "
+ "FROM Building b")
List<BuildingListDto> findAllAsDto();쿼리 단에서 필요한 컬럼만 SELECT하기 때문에 네트워크/메모리를 절약할 수 있고, 영속성 컨텍스트에 엔티티가 올라가지 않아서 dirty check 오버헤드도 없습니다.
단점은 FQCN(패키지 전체 경로)을 JPQL에 써야 해서, 패키지를 이동하면 런타임에 터집니다.
org.hibernate.hql.internal.ast.QuerySyntaxException:
Unable to locate class [com.example.dto.BuildingDto]
또한 파라미터 순서에 의존하기 때문에, DTO 생성자 시그니처가 바뀌면 역시 런타임 에러입니다. 컴파일 타임에 못 잡는다는 게 꽤 큰 단점입니다.
3. Spring Data Projection (인터페이스 기반)#
// 인터페이스 프로젝션 -- 구현체를 Spring이 프록시로 생성
public interface BuildingListView {
Long getId();
String getName();
String getRegionName();
}
public interface BuildingRepository extends JpaRepository<Building, Long> {
List<BuildingListView> findAllBy(); // 반환 타입만 바꾸면 됨
}Spring Data가 프록시를 만들어서, SELECT절에 인터페이스의 getter에 해당하는 컬럼만 포함시킵니다. (Spring Data JPA - Projections) DTO 클래스를 직접 만들 필요가 없어서 편합니다.
주의할 점은, SpEL을 쓰는 열린 프로젝션(Open Projection)을 쓰면 SELECT 최적화가 사라지고 SELECT *로 퇴화합니다.
// 이러면 엔티티 전체를 로딩함 -- SELECT 최적화 없음
public interface BuildingListView {
@Value("#{target.name + ' (' + target.region.name + ')'}")
String getDisplayName();
}닫힌 프로젝션(Closed Projection)만 SELECT 최적화가 적용됩니다.
4. MapStruct#
엔티티-DTO 변환이 반복되는 경우에 도입했습니다. 컴파일 타임에 매핑 코드를 생성해주기 때문에 런타임 오버헤드가 없고, 필드명이 같으면 자동으로 매핑됩니다.
@Mapper(componentModel = "spring")
public interface BuildingMapper {
BuildingResponseDto toDto(Building building);
}단순 매핑이 아니라 비즈니스 로직이 섞인 변환이 필요하면 @AfterMapping을 씁니다.
@Mapper(componentModel = "spring")
public interface BuildingMapper {
@Mapping(target = "statusLabel", ignore = true)
BuildingDetailDto toDetailDto(Building building);
@AfterMapping
default void enrichDetailDto(Building source, @MappingTarget BuildingDetailDto target) {
if (source.getStatus() == BuildingStatus.ACTIVE
&& source.getFloors().size() > 10) {
target.setStatusLabel("대형 운영중");
} else if (source.getStatus() == BuildingStatus.ACTIVE) {
target.setStatusLabel("운영중");
} else {
target.setStatusLabel("비활성");
}
}
}다만 커스텀 로직이 많아지면 MapStruct 설정이 오히려 복잡해져서, 단순 1:1 매핑에만 쓰고 복잡한 건 팩토리 메서드로 처리했습니다.
방식 비교#
| 방식 | 장점 | 단점 | 적합한 경우 |
|---|---|---|---|
| 팩토리 메서드 | 명시적, 추적 쉬움 | 필드 많으면 보일러플레이트 | 대부분의 경우 |
| JPQL Constructor | SELECT 최적화, dirty check 없음 | FQCN 깨짐, 순서 의존 | 목록 조회 성능이 중요할 때 |
| Interface Projection | 클래스 생성 불필요 | Open Projection 함정, 복잡한 변환 불가 | 단순 읽기 전용 조회 |
| MapStruct | 컴파일 타임 생성, 타입 안전 | 학습 곡선, 복잡한 매핑 시 설정 과다 | 반복적 매핑이 많을 때 |
하나의 엔티티, 여러 DTO#
DTO 분리의 실질적인 이점이 가장 드러나는 케이스입니다. 같은 엔티티를 다른 API에서 다른 형태로 내보내야 할 때.
// 목록 조회 -- 최소 정보만
public record BuildingListDto(Long id, String name, String regionName) {}
// 상세 조회 -- 연관 데이터 포함
public record BuildingDetailDto(
Long id, String name, String address,
RegionDto region, List<FloorDto> floors,
LocalDateTime createdAt
) {}
// 관리자 전용 -- 내부 메타 포함
public record BuildingAdminDto(
Long id, String name, String internalCode,
BigDecimal monthlyRevenue,
List<AuditLogDto> recentAuditLogs
) {}@RestController
@RequestMapping("/buildings")
public class BuildingController {
@GetMapping
public List<BuildingListDto> list() {
return buildingQueryService.findAllAsList(); // join 없이 단일 테이블
}
@GetMapping("/{id}")
public BuildingDetailDto detail(@PathVariable Long id) {
return buildingQueryService.findDetail(id); // fetch join
}
@GetMapping("/{id}/admin")
@PreAuthorize("hasRole('ADMIN')")
public BuildingAdminDto adminDetail(@PathVariable Long id) {
return buildingQueryService.findAdminDetail(id); // 감사로그 join
}
}핵심은 DTO가 쿼리를 결정한다는 점입니다. 목록용 DTO는 join 없이 단일 테이블 조회, 상세용 DTO는 fetch join, 관리자용 DTO는 추가 테이블 join. 엔티티 하나를 반환하면 이런 쿼리 최적화가 불가능합니다.
@JsonView로 하나의 엔티티에서 여러 뷰를 표현하는 방법도 있지만, 엔티티가 Jackson 어노테이션으로 오염되고 SELECT 최적화가 안 되기 때문에 DTO 분리가 더 낫다고 판단했습니다.
@Transient vs @Formula#
DTO로 전환하면서 @Transient 대신 @Formula를 고려한 적도 있습니다.
@Entity
public class Building {
@Id
private Long id;
private String name;
// @Transient: Hibernate가 완전히 무시. dirty check 대상 아님.
@Transient
private double distanceFromUser;
// @Formula: DB에서 서브쿼리로 계산. 읽기 전용.
@Formula("(SELECT COUNT(*) FROM floor f WHERE f.building_id = id)")
private int floorCount;
}| dirty check | UPDATE 포함 | SELECT 시 | |
|---|---|---|---|
@Transient | X | X | DB 접근 안 함 |
@Formula | X (읽기 전용) | X | 서브쿼리 실행 |
| 일반 컬럼 | O | O | O |
@Formula는 findById 같은 단건 조회에서는 괜찮지만, findAll()에서는 건물마다 서브쿼리가 실행되면서 성능 문제가 됩니다. 결국 목록 API에서는 JPQL 집계나 DTO 프로젝션이 답이었습니다.
주의할 점 하나 더: @Formula 필드에 값을 set해도 flush 시 UPDATE에 포함되지 않습니다. Hibernate는 @Formula를 읽기 전용으로 취급하기 때문입니다.
트레이드오프#
DTO 분리가 무조건 좋은 건 아닙니다.
파일 수가 늘어납니다. 엔티티가 30개이고 각각 요청/응답 DTO를 만들면 60개의 DTO 클래스가 추가됩니다. Java record를 쓰면 보일러플레이트는 줄지만 파일 수 자체는 줄지 않습니다.
변환 코드를 관리해야 합니다. 엔티티에 필드가 추가되면 DTO와 매퍼도 같이 수정해야 합니다. 빼먹으면 API 응답에서 새 필드가 누락됩니다.
프로토타이핑 단계에서는 과합니다. API 스펙이 안 정해졌고 엔티티 구조도 매일 바뀌는 상황에서 DTO를 미리 만들면 변경할 때마다 엔티티, DTO, 매퍼 세 곳을 고쳐야 합니다.
언제 @Transient가 괜찮은가#
- 프로토타이핑/PoC 단계: API 스펙이 자주 바뀌는 초기에는 엔티티를 직접 반환하는 게 빠릅니다
- 내부용 어드민 API: 외부에 노출되지 않는 관리자 API에서 엔티티 필드를 그대로 보여줘도 문제없는 경우
- @Transient 필드가 1-2개: 엔티티가 비대해지지 않는 수준이면 별도 DTO를 만드는 게 오버엔지니어링입니다
결국 엔티티를 열었을 때 DB 컬럼이 아닌 필드가 눈에 띌 정도로 많아졌다면 분리 시점입니다. 저의 경우 @Transient 필드가 5개를 넘어가면서 전환을 결심했습니다.
정리#
프로젝트 초기에 @Transient로 빠르게 해결한 건 잘못된 선택이 아니었습니다. 문제는 그 상태를 계속 유지한 것입니다. 기능이 늘어나면서 엔티티가 비대해졌고, 직렬화 혼란(javax.persistence.Transient와 Jackson의 무관함), Hibernate 프록시 문제, N+1이 연쇄적으로 터지면서 DTO 분리로 전환했습니다.
전환 후 엔티티는 DB 매핑만 담당하게 되면서 의도가 명확해졌고, API별로 최적화된 쿼리를 쓸 수 있게 됐습니다. 요즘은 처음부터 record 기반 DTO를 만드는 편입니다. 보일러플레이트가 적어서 부담이 크지 않고, 나중에 "엔티티에서 분리해야 하나?"를 고민할 필요가 없어지니까요.