스프링 프로젝트에 Langfuse 도입하기 [1] — 프롬프트 관리와 트레이싱
왜 Langfuse인가#
사내에서 LLM을 쓰는 서비스가 3개로 늘어나면서, 프롬프트 관리가 슬슬 문제가 되기 시작했습니다. 처음에는 프롬프트를 코드에 하드코딩해서 썼는데, 프롬프트를 한 글자 고치려면 배포를 해야 했습니다. 프롬프트 엔지니어링을 반복하는 과정에서 이건 좀 아니다 싶었습니다.
프롬프트를 코드 밖으로 빼야 했고, 버전 관리도 되어야 하고, 환경별로 다른 프롬프트를 쓸 수 있어야 했습니다. 거기에 LLM 호출이 실제로 어떻게 동작하는지 — 어떤 프롬프트 버전으로, 어떤 모델에, 얼마나 걸렸는지 — 볼 수 있는 트레이싱도 필요했습니다.
Langfuse는 이 두 가지를 동시에 해결해줍니다. 프롬프트 버전 관리 + LLM 호출 트레이싱을 하나의 플랫폼에서 제공하는 오픈소스 도구입니다. GitHub 스타 22k+로 LLM 관측 도구 중에서는 가장 활발한 편이고, 클라우드 호스팅과 셀프 호스팅 둘 다 가능합니다. 2025년 3월에 Java 클라이언트가 공식 릴리즈되면서 Spring 프로젝트에도 바로 붙일 수 있게 됐습니다.
이 글은 실제 프로덕션에서 운영 중인 3개 프로젝트의 코드를 바탕으로, Spring Boot에 Langfuse를 붙이면서 어떤 식으로 정리했는지 적어둔 기록에 가깝습니다.
Langfuse가 해주는 것#
코드로 들어가기 전에, Langfuse를 왜 골랐는지에 가까운 지점 두 가지만 먼저 짚고 가겠습니다.
프롬프트 관리 — 대시보드에서 프롬프트를 등록하고, 버전을 올리고, 환경별 라벨(production, development)을 붙일 수 있습니다. 코드에서는 프롬프트 이름만으로 조회하면 되고, 배포 없이 프롬프트를 바꿀 수 있습니다. config에 모델명이나 temperature 같은 파라미터를 함께 저장할 수도 있어서, 프롬프트와 모델 설정을 한 곳에서 관리할 수 있습니다.
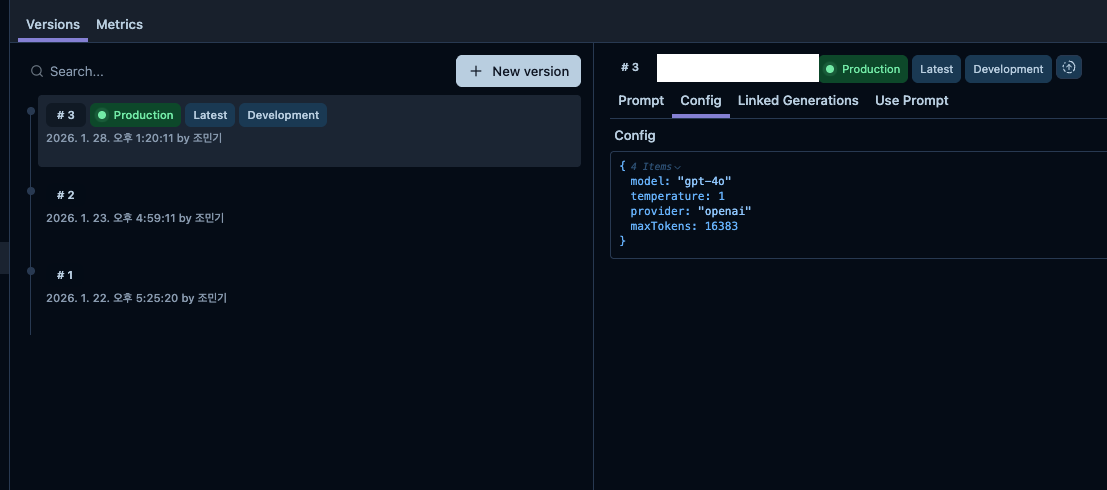
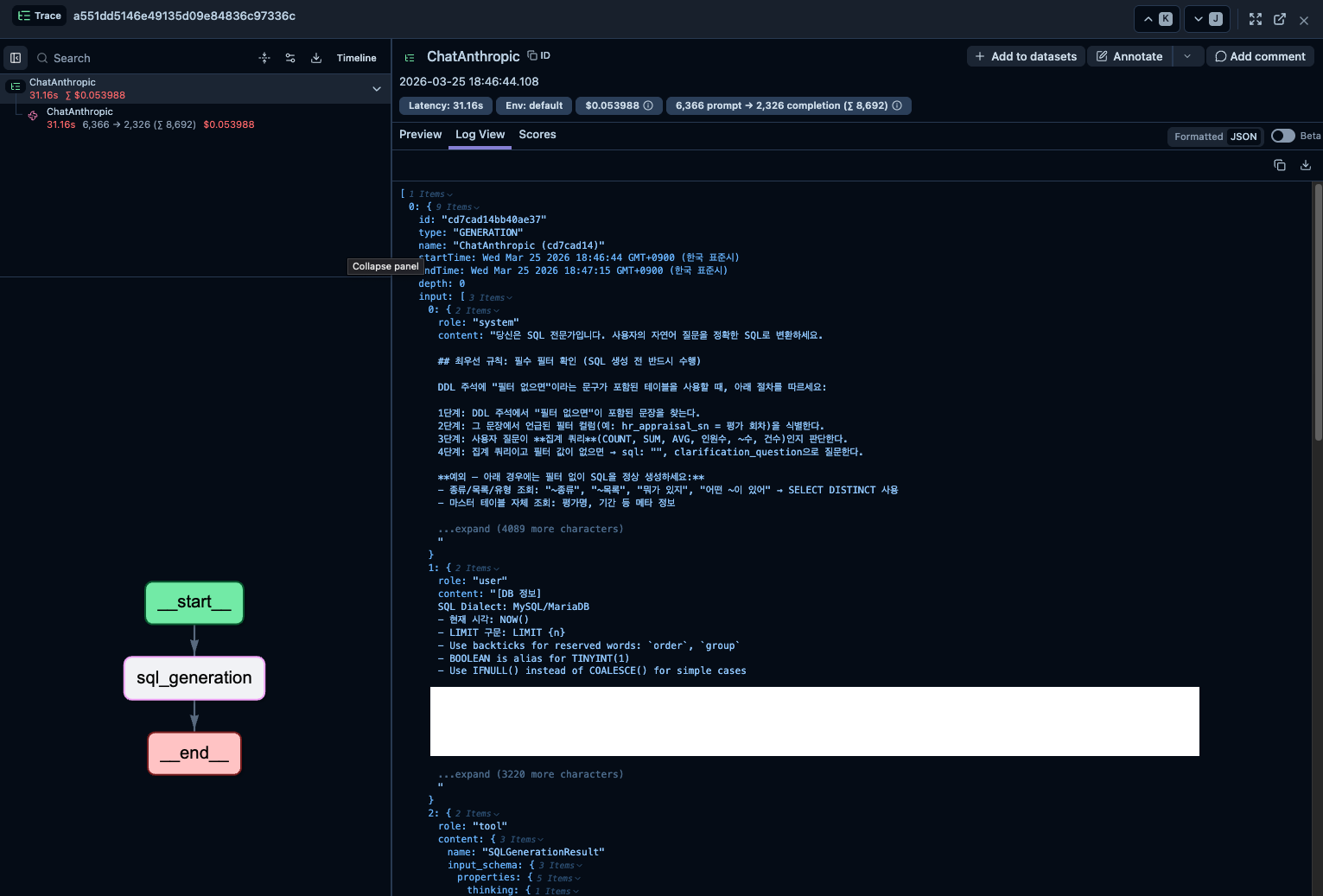
트레이싱 — LLM 호출의 입력, 출력, 소요 시간, 사용 모델, 프롬프트 버전 등을 자동으로 기록합니다. Trace(요청 단위) 안에 Generation(LLM 호출 단위)이 중첩되는 구조라서, 여러 번의 LLM 호출이 하나의 요청 안에서 어떻게 연결되는지 한눈에 볼 수 있습니다.
Langfuse 셋업#
코드를 작성하기 전에 Langfuse 쪽 준비가 먼저 필요합니다. 순서는 간단합니다.
1. 프로젝트 생성 — Langfuse Cloud에 가입하거나, 셀프 호스팅으로 직접 띄웁니다. 가입하면 프로젝트가 하나 생기고, Settings에서 API 키를 발급받을 수 있습니다. Public Key와 Secret Key 두 개가 필요합니다.
2. 프롬프트 등록 — 대시보드에서 Prompts 메뉴로 들어가서 프롬프트를 만듭니다. 이름을 정하고(document_summary 같은), 프롬프트 텍스트를 작성합니다. {{variableName}} 형태로 변수를 넣을 수 있고, Config 탭에서 model, temperature, provider 같은 파라미터도 함께 저장합니다.
3. 라벨 지정 — 프롬프트 버전을 만들면 latest 라벨이 자동으로 붙습니다. 프로덕션에 배포할 버전에는 production 라벨을, 개발 중인 버전에는 development 라벨을 수동으로 붙입니다. 코드에서는 이 라벨로 어떤 버전을 가져올지 결정합니다.
여기까지 하면 Langfuse 쪽 준비는 끝입니다. 이제 Spring 코드에서 이 프롬프트를 가져다 쓰는 구조를 만들어봅니다.
의존성 추가#
<dependency>
<groupId>com.langfuse</groupId>
<artifactId>langfuse-java</artifactId>
<version>0.1.2</version>
</dependency>Gradle이면 이렇게 됩니다.
implementation 'com.langfuse:langfuse-java:0.1.2'Langfuse Java SDK는 내부적으로 OkHttp를 쓰기 때문에, OkHttp 관련 의존성이 이미 있으면 버전 충돌을 확인해야 합니다. SDK 소스는 langfuse/langfuse-java에서 확인할 수 있습니다.
참고: Langfuse는 Spring AI + OpenTelemetry 연동도 지원합니다. Spring AI를 이미 쓰고 있다면 OTel 기반으로 자동 트레이싱을 붙이는 방법도 있습니다. 여기서는 SDK를 직접 쓰는 쪽으로 갔습니다 — 프롬프트 관리 API를 함께 쓰려면 이쪽이 더 유연합니다.
LangfuseClient 설정#
Langfuse와 통신하는 클라이언트 빈을 만들 때 먼저 챙긴 건 두 가지였습니다. 환경별 on/off와 HTTP 연결 풀 관리입니다.
@Configuration
@ConditionalOnProperty(prefix = "langfuse", name = "enabled", havingValue = "true")
public class LangfuseConfig {
@Value("${langfuse.public-key}")
private String publicKey;
@Value("${langfuse.secret-key}")
private String secretKey;
@Value("${langfuse.base-url}")
private String baseUrl;
@Value("${langfuse.okhttp.keepalive.duration:20}")
private int keepAliveDuration;
@Value("${langfuse.okhttp.connection.pool.max:20}")
private int maxIdleConnections;
@Bean
public OkHttpClient langfuseOkHttpClient() {
ConnectionPool pool = new ConnectionPool(
maxIdleConnections,
keepAliveDuration,
TimeUnit.SECONDS
);
return new OkHttpClient.Builder()
.connectionPool(pool)
.build();
}
@Bean
public LangfuseClient langfuseClient(OkHttpClient langfuseOkHttpClient) {
return LangfuseClient.builder()
.url(baseUrl)
.credentials(publicKey, secretKey)
.httpClient(langfuseOkHttpClient)
.timeout(10)
.build();
}
}@ConditionalOnProperty로 langfuse.enabled=true일 때만 빈이 생성됩니다. 로컬 개발 환경에서는 Langfuse 없이도 애플리케이션이 뜨게 하려는 의도인데, 이건 뒤에서 NoOp 패턴과 함께 설명합니다.
OkHttp ConnectionPool을 별도로 설정하는 이유는, LLM 호출마다 Langfuse에 트레이싱 데이터를 보내야 해서 HTTP 연결이 빈번하게 발생하기 때문입니다. 기본 설정으로 두면 연결 생성/해제 오버헤드가 쌓입니다.
application.yml#
langfuse:
enabled: true
base-url: https://us.cloud.langfuse.com
public-key: ${LANGFUSE_PUBLIC_KEY}
secret-key: ${LANGFUSE_SECRET_KEY}
okhttp:
keepalive:
duration: 20
connection:
pool:
max: 20
cache:
ttl-seconds: 1800
trace:
enabled: true키 값은 환경변수나 AWS Parameter Store 같은 외부 저장소에서 주입합니다. 코드에 하드코딩하면 안 되는 건 당연하고, 로그에 찍힐 때도 마스킹 처리가 필요합니다.
String maskedKey = publicKey != null && publicKey.length() > 4
? "****" + publicKey.substring(publicKey.length() - 4)
: "NOT_SET";
log.info("[LangfuseConfig] publicKey: {}", maskedKey);프롬프트 관리#
Langfuse의 가장 큰 가치는 프롬프트를 코드 밖에서 관리할 수 있다는 점입니다. Langfuse 대시보드에서 프롬프트를 등록하고, 버전을 올리고, 환경별 라벨을 붙이면 — 코드에서는 이름만으로 가져다 씁니다. (공식 문서: Prompt Management)
Langfuse에서 프롬프트 버전을 올리면 이전 버전과 diff를 비교할 수 있고, 특정 버전에 production 라벨을 붙여서 배포 대상을 지정합니다.
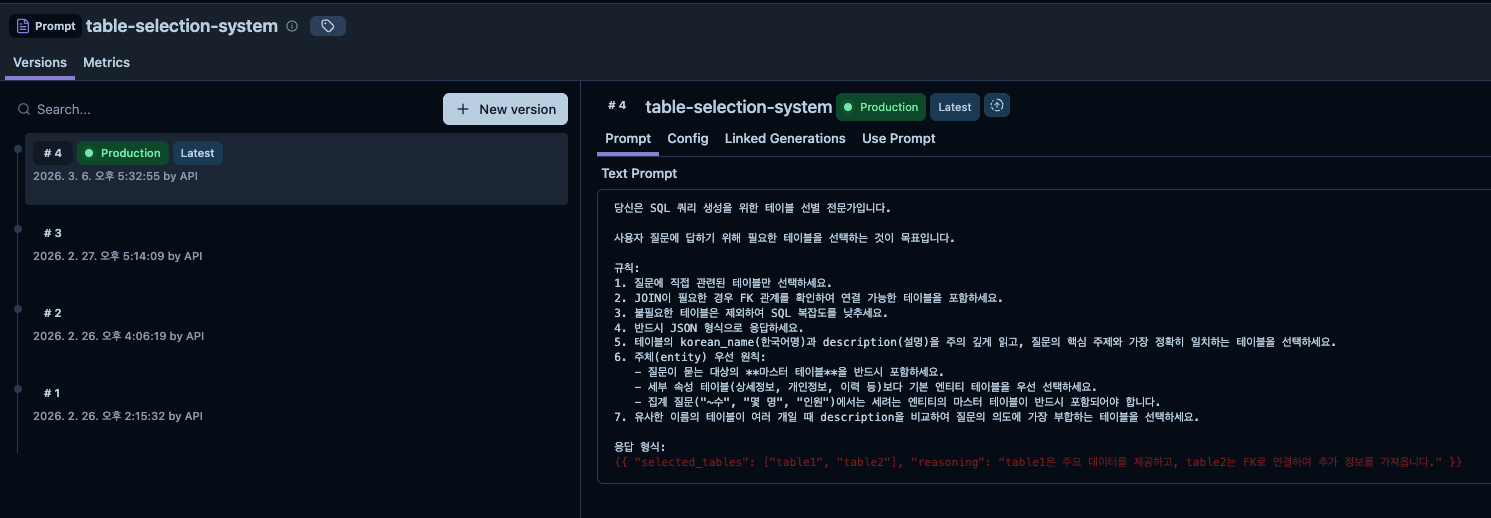
이제 이걸 Spring 코드에서 가져다 쓰는 구조를 만들어봅니다.
프롬프트 서비스 인터페이스#
public interface LangfusePromptService {
PromptWithConfig resolvePrompt(LLMPromptRequest request);
}반환 타입인 PromptWithConfig에는 프롬프트 텍스트뿐 아니라 Langfuse에서 설정한 모델 정보도 함께 들어옵니다.
public record PromptWithConfig(
String promptText,
PromptConfigData config,
String promptName,
Integer promptVersion
) {
public static PromptWithConfig fallback(String text, String name) {
return new PromptWithConfig(text, PromptConfigData.defaults(), name, null);
}
}PromptConfigData는 Langfuse 프롬프트에 붙여둔 config를 담는 객체입니다. provider, model, temperature, maxTokens를 여기서 관리하면 프롬프트와 모델 설정을 한 곳에서 바꿀 수 있습니다.
public class PromptConfigData {
private String provider; // "openai", "anthropic"
private String model; // "gpt-4o", "claude-sonnet-4-20250514"
private Double temperature;
private Integer maxTokens;
public String getProviderOrDefault() {
return provider != null ? provider : "openai";
}
public String getModelOrDefault() {
return model != null ? model : "gpt-4o";
}
}프롬프트 요청#
public record LLMPromptRequest(
String promptName,
Map<String, Object> promptVariables,
String fallbackPrompt
) {
public static LLMPromptRequest of(String promptName) {
return new LLMPromptRequest(promptName, Map.of(), null);
}
public static LLMPromptRequest of(String promptName,
Map<String, Object> variables,
String fallbackPrompt) {
return new LLMPromptRequest(promptName, variables, fallbackPrompt);
}
}fallbackPrompt가 핵심입니다. Langfuse 서버가 죽거나 프롬프트를 못 찾으면 이 텍스트가 대신 사용됩니다. 프로덕션에서 외부 의존성 하나 때문에 전체 서비스가 멈추면 안 되니까요.
변수 치환#
Langfuse 프롬프트 안에 {{variableName}} 형태로 변수를 넣어두면, 코드에서 실제 값으로 치환합니다.
public class PromptVariableReplacer {
private static final Pattern VARIABLE_PATTERN =
Pattern.compile("\\{\\{(\\w+(?:\\.\\w+)*)}}");
public static String replace(String template, Map<String, Object> variables) {
if (template == null || variables == null || variables.isEmpty()) {
return template;
}
Matcher matcher = VARIABLE_PATTERN.matcher(template);
StringBuilder result = new StringBuilder();
while (matcher.find()) {
String varName = matcher.group(1);
Object value = variables.get(varName);
if (value != null) {
matcher.appendReplacement(result,
Matcher.quoteReplacement(String.valueOf(value)));
}
}
matcher.appendTail(result);
return result.toString();
}
}Matcher.quoteReplacement을 쓰는 이유가 있습니다. 변수 값에 $나 \ 같은 정규식 특수문자가 들어오면 치환이 깨지기 때문에, 이걸로 이스케이프 처리를 합니다. 변수가 map에 없으면 {{variableName}} 그대로 남겨둡니다.
환경별 라벨#
프로덕션과 개발 환경에서 다른 프롬프트를 쓰고 싶을 때, Langfuse의 라벨 기능을 활용합니다. Langfuse 자체는 라벨을 붙이는 기능만 제공하고, 라벨 간 우선순위나 fallback 같은 건 지원하지 않습니다. 그래서 환경별로 라벨을 단계적으로 시도하는 fallback 체인을 직접 설계했습니다.
public enum PromptLabel {
DEV("development"),
PR("production"),
LATEST("latest");
private final String value;
public List<PromptLabel> fallbackChain() {
return switch (this) {
case DEV -> List.of(DEV, PR, LATEST);
case PR -> List.of(PR, LATEST);
case LATEST -> List.of(LATEST);
};
}
}DEV 환경에서 프롬프트를 조회하면 development 라벨을 먼저 찾고, 없으면 production, 그래도 없으면 latest까지 시도합니다. 이렇게 만든 이유는, 실제로 프롬프트를 운영하다 보면 모든 환경에 라벨을 다 붙여놓지 않는 경우가 많기 때문입니다. 새 프롬프트를 만들면 보통 production 라벨만 달아두는데, 이때 DEV 환경에서도 그 프롬프트가 동작해야 합니다. fallback 체인이 없으면 DEV에서 development 라벨을 못 찾아서 에러가 나고, 그때마다 Langfuse에 가서 라벨을 붙여야 하는 번거로움이 생깁니다.
이 설계의 디테일 — 캐싱과 결합했을 때의 동작, Langfuse 서버 장애 시 최종 fallback까지의 흐름 — 은 다음 편에서 조금 더 자세히 풀어둡니다.
어떤 환경에서 어떤 라벨을 쓸지는 Spring 프로필로 결정합니다.
@Component
public class LangfuseEnvironmentConfig {
@Value("${spring.profiles.active:local}")
private String activeProfile;
public PromptLabel getPromptLabel() {
if ("production".equals(activeProfile)) {
return PromptLabel.PR;
}
return PromptLabel.DEV;
}
}프롬프트 서비스 구현#
위의 조각들을 모아서 실제 프롬프트 조회 로직을 만듭니다.
@Service
@ConditionalOnProperty(prefix = "langfuse", name = "enabled", havingValue = "true")
@RequiredArgsConstructor
public class LangfusePromptServiceImpl implements LangfusePromptService {
private final LangfuseClient langfuseClient;
private final LangfuseEnvironmentConfig envConfig;
@Override
public PromptWithConfig resolvePrompt(LLMPromptRequest request) {
PromptLabel label = envConfig.getPromptLabel();
for (PromptLabel candidate : label.fallbackChain()) {
try {
return getPrompt(
request.promptName(),
candidate,
request.promptVariables()
);
} catch (PromptLoadException e) {
log.warn("[Langfuse] {} 라벨로 프롬프트 조회 실패, 다음 시도",
candidate.getValue());
}
}
// 모든 라벨 실패 → fallback 프롬프트 사용
String compiled = PromptVariableReplacer.replace(
request.fallbackPrompt(),
request.promptVariables()
);
return PromptWithConfig.fallback(compiled, request.promptName());
}
private PromptWithConfig getPrompt(String promptName,
PromptLabel label,
Map<String, Object> variables) {
GetPromptRequest getRequest = GetPromptRequest.builder()
.label(label.getValue())
.build();
Prompt prompt = langfuseClient.prompts()
.get(promptName, getRequest);
String text = PromptExtractor.extractText(prompt);
PromptConfigData config = PromptExtractor.extractConfig(prompt);
Integer version = PromptExtractor.extractVersion(prompt);
String compiled = PromptVariableReplacer.replace(text, variables);
return PromptWithConfig.of(compiled, config, promptName, version);
}
}여기까지 묶으면 호출 흐름은 이렇습니다:
PromptExtractor — Langfuse 응답 파싱#
위 코드에서 PromptExtractor가 등장하는데, 이건 Langfuse SDK가 돌려주는 Prompt 객체에서 텍스트, 설정, 버전을 꺼내는 유틸리티입니다. Langfuse 프롬프트에는 Text 타입과 Chat 타입 두 가지가 있어서, 타입에 따라 추출 방식이 다릅니다.
public final class PromptExtractor {
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper()
.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
public static String extractText(Prompt prompt) {
if (prompt.isText()) {
return prompt.getText()
.orElseThrow(() -> new PromptLoadException("Text prompt is empty"))
.getPrompt();
}
if (prompt.isChat()) {
ChatPrompt chatPrompt = prompt.getChat()
.orElseThrow(() -> new PromptLoadException("Chat prompt is empty"));
// Chat 프롬프트는 여러 메시지(system, user 등)를 줄바꿈으로 결합
StringBuilder combined = new StringBuilder();
for (ChatMessageWithPlaceholders msg : chatPrompt.getPrompt()) {
if (msg.isChatmessage() && msg.getChatmessage().isPresent()) {
if (!combined.isEmpty()) combined.append("\n\n");
combined.append(msg.getChatmessage().get().getContent());
}
}
return combined.toString();
}
throw new PromptLoadException("Unknown prompt type");
}
public static PromptConfigData extractConfig(Prompt prompt) {
try {
Object config = prompt.isText()
? prompt.getText().map(TextPrompt::getConfig).orElse(null)
: prompt.getChat().map(ChatPrompt::getConfig).orElse(null);
if (config != null) {
return OBJECT_MAPPER.convertValue(config, PromptConfigData.class);
}
} catch (Exception e) {
log.warn("[PromptExtractor] config 추출 실패", e);
}
return PromptConfigData.defaults();
}
public static Integer extractVersion(Prompt prompt) {
if (prompt.isText()) return prompt.getText().map(TextPrompt::getVersion).orElse(null);
if (prompt.isChat()) return prompt.getChat().map(ChatPrompt::getVersion).orElse(null);
return null;
}
}Chat 타입 프롬프트를 쓰면 system/user 메시지를 역할별로 나눠서 관리할 수 있어서 편한데, SDK에서 꺼낼 때는 메시지들을 하나로 합쳐야 합니다. extractConfig에서 FAIL_ON_UNKNOWN_PROPERTIES를 꺼두는 건, Langfuse 쪽에서 config 필드가 추가되더라도 역직렬화가 깨지지 않게 하려는 방어 코드입니다.
트레이싱#
프롬프트 관리만으로도 가치가 있지만, 트레이싱이 붙으면 LLM 호출의 전체 그림이 보입니다. 어떤 프롬프트 버전으로, 어떤 모델에, 무엇을 보내서, 무엇을 받았고, 얼마나 걸렸는지. (공식 문서: Observability)
Trace와 Generation#
Langfuse의 트레이싱 데이터 모델은 두 가지 핵심 개념으로 나뉩니다:
- Trace: 하나의 요청 단위. 사용자가 "이 문서 요약해줘"라고 하면 그게 하나의 Trace입니다
- Generation: Trace 안에서 실제로 발생한 LLM 호출. 하나의 Trace에 여러 Generation이 있을 수 있습니다 (체인 호출 등)
Langfuse 대시보드에서는 Trace 목록을 한눈에 볼 수 있고, 각 Trace를 클릭하면 안에 포함된 Generation들의 상세 정보를 확인할 수 있습니다.
요청 DTO#
public record TraceRequest(
String name,
Object input,
Map<String, Object> metadata
) {}
public record GenerationRequest(
String traceId,
String name,
String model,
Object input,
Object output,
Map<String, Object> metadata,
OffsetDateTime startTime
) {
public String promptName() {
return metadata != null ? (String) metadata.get("promptName") : null;
}
public Integer promptVersion() {
Object value = metadata != null ? metadata.get("promptVersion") : null;
if (value instanceof Integer i) return i;
if (value instanceof Number n) return n.intValue();
return null;
}
}GenerationRequest에서 startTime을 받는 이유는, LLM 호출 전에 시간을 찍어두고 Generation 생성 시점과 비교해서 latency를 계산하기 위해서입니다. Langfuse 대시보드에서 호출별 소요 시간을 볼 수 있습니다.
트레이스 서비스#
public interface LangfuseTraceService {
boolean isEnabled();
String createTrace(TraceRequest request);
void recordGeneration(GenerationRequest request);
void endTrace(String traceId, Object output);
void flush();
}구현체에서 중요한 부분은 이벤트 버퍼링입니다. LLM 호출할 때마다 Langfuse API를 바로 찌르면 네트워크 오버헤드가 쌓이기 때문에, 이벤트를 버퍼에 모았다가 일정 개수가 차면 배치로 보냅니다.
@Service
@ConditionalOnProperty(prefix = "langfuse.trace", name = "enabled", havingValue = "true")
@RequiredArgsConstructor
public class LangfuseTraceServiceImpl implements LangfuseTraceService {
private final LangfuseClient langfuseClient;
private final ConcurrentLinkedQueue<IngestionEvent> eventBuffer
= new ConcurrentLinkedQueue<>();
private static final int BATCH_SIZE = 10;
@Override
public boolean isEnabled() { return true; }
@Override
public String createTrace(TraceRequest request) {
String traceId = UUID.randomUUID().toString();
OffsetDateTime now = OffsetDateTime.now();
TraceEvent traceEvent = TraceEvent.builder()
.id(UUID.randomUUID().toString())
.timestamp(now.format(DateTimeFormatter.ISO_OFFSET_DATE_TIME))
.body(TraceBody.builder()
.id(traceId)
.name(request.name())
.timestamp(now)
.input(request.input())
.metadata(request.metadata())
.build())
.build();
addToBuffer(IngestionEvent.traceCreate(traceEvent));
return traceId;
}
@Override
public void recordGeneration(GenerationRequest request) {
String generationId = UUID.randomUUID().toString();
OffsetDateTime now = OffsetDateTime.now();
CreateGenerationEvent event = CreateGenerationEvent.builder()
.id(UUID.randomUUID().toString())
.timestamp(now.format(DateTimeFormatter.ISO_OFFSET_DATE_TIME))
.body(CreateGenerationBody.builder()
.id(generationId)
.traceId(request.traceId())
.name(request.name())
.model(request.model())
.startTime(request.startTime())
.endTime(now)
.input(request.input())
.output(request.output())
.promptName(request.promptName())
.promptVersion(request.promptVersion())
.metadata(request.metadata())
.build())
.build();
addToBuffer(IngestionEvent.generationCreate(event));
}
@Override
public void endTrace(String traceId, Object output) {
OffsetDateTime now = OffsetDateTime.now();
TraceEvent traceEvent = TraceEvent.builder()
.id(UUID.randomUUID().toString())
.timestamp(now.format(DateTimeFormatter.ISO_OFFSET_DATE_TIME))
.body(TraceBody.builder()
.id(traceId)
.output(output)
.build())
.build();
addToBuffer(IngestionEvent.traceCreate(traceEvent));
flush();
}
@Override
public void flush() {
List<IngestionEvent> events = new ArrayList<>();
IngestionEvent event;
while ((event = eventBuffer.poll()) != null) {
events.add(event);
}
if (events.isEmpty()) return;
try {
IngestionRequest request = IngestionRequest.builder()
.batch(events)
.build();
langfuseClient.ingestion().batch(request);
} catch (Exception e) {
log.error("[LangfuseTrace] flush 실패", e);
}
}
private void addToBuffer(IngestionEvent event) {
eventBuffer.add(event);
if (eventBuffer.size() >= BATCH_SIZE) {
flush();
}
}
}ConcurrentLinkedQueue를 쓰는 이유는 여러 스레드에서 동시에 이벤트를 넣을 수 있기 때문입니다. endTrace에서는 항상 flush()를 호출해서, Trace가 끝나면 남아있는 이벤트를 모두 보냅니다.
한 가지 주의할 점이 있습니다. 버퍼에 이벤트가 9개 쌓인 상태로 애플리케이션이 종료되면, 그 이벤트들은 유실됩니다. Graceful Shutdown 시 flush()를 호출하는 @PreDestroy 처리를 넣어두는 게 좋습니다.
NoOp 패턴#
로컬 개발 환경에서는 Langfuse 키도 없고, 트레이싱도 필요 없습니다. 그렇다고 Langfuse 설정이 없으면 애플리케이션이 안 뜨게 하면 곤란하니까, 비활성화 환경에서는 아무것도 안 하는 구현체를 만들어둡니다.
@Service
@ConditionalOnProperty(
prefix = "langfuse", name = "enabled",
havingValue = "false", matchIfMissing = true
)
public class NoOpLangfusePromptService implements LangfusePromptService {
@Override
public PromptWithConfig resolvePrompt(LLMPromptRequest request) {
String compiled = PromptVariableReplacer.replace(
request.fallbackPrompt(),
request.promptVariables()
);
return PromptWithConfig.fallback(compiled, request.promptName());
}
}@Service
@ConditionalOnProperty(
prefix = "langfuse.trace", name = "enabled",
havingValue = "false", matchIfMissing = true
)
public class NoOpLangfuseTraceService implements LangfuseTraceService {
@Override
public boolean isEnabled() { return false; }
@Override
public String createTrace(TraceRequest request) {
return UUID.randomUUID().toString();
}
@Override
public void recordGeneration(GenerationRequest request) { }
@Override
public void endTrace(String traceId, Object output) { }
@Override
public void flush() { }
}matchIfMissing = true가 포인트입니다. langfuse.enabled 설정 자체가 없으면 NoOp이 활성화됩니다. 설정을 안 했을 때 기본적으로 안전한 쪽으로 동작하게 만드는 거죠.
이 구조의 장점은, LLM 호출 코드에서 Langfuse 활성화 여부를 전혀 신경 쓸 필요가 없다는 점입니다. 인터페이스만 주입받으면 환경에 따라 알아서 실제 구현체 또는 NoOp이 들어옵니다.
| 설정 | Prompt Service | Trace Service |
|---|---|---|
enabled=true, trace.enabled=true | 실제 구현체 | 실제 구현체 |
enabled=true, trace.enabled=false | 실제 구현체 | NoOp |
enabled=false 또는 미설정 | NoOp | NoOp |
프롬프트는 Langfuse에서 가져오되 트레이싱은 끄고 싶은 경우처럼, 기능별로 독립적으로 on/off할 수 있습니다.
LLMService에서의 통합#
프롬프트 서비스와 트레이스 서비스를 실제 LLM 호출 코드에 조합하면 이런 모양이 됩니다.
@Component
@RequiredArgsConstructor
public class LLMServiceImpl implements LLMService {
private final ChatModelSelector chatModelSelector;
private final LangfusePromptService langfusePromptService;
private final LangfuseTraceService langfuseTraceService;
@Override
public <T> T chat(LLMPromptRequest promptRequest,
Collection<LLMMessage> messages,
Class<T> responseType) {
// 1. 프롬프트 조회 (Langfuse or fallback)
PromptWithConfig prompt = langfusePromptService.resolvePrompt(promptRequest);
// 2. Config에서 provider/model 결정
ChatModel chatModel = chatModelSelector.select(prompt.config());
// 3. 메타데이터 구성
Map<String, Object> metadata = Map.of(
"provider", prompt.config().getProviderOrDefault(),
"model", prompt.config().getModelOrDefault(),
"promptName", prompt.promptName(),
"promptVersion", prompt.promptVersion() != null ? prompt.promptVersion() : 0
);
OffsetDateTime startTime = OffsetDateTime.now();
try {
// 4. LLM 호출
String rawResponse = chatModel.call(prompt.promptText(), messages);
T response = parseResponse(rawResponse, responseType);
// 5. 성공 트레이싱
String traceId = langfuseTraceService.createTrace(
new TraceRequest(prompt.promptName(), messages, metadata));
langfuseTraceService.recordGeneration(
new GenerationRequest(
traceId, prompt.promptName(),
prompt.config().getModelOrDefault(),
messages, response, metadata, startTime));
langfuseTraceService.endTrace(traceId, response);
return response;
} catch (Exception e) {
// 6. 실패 트레이싱
String traceId = langfuseTraceService.createTrace(
new TraceRequest(prompt.promptName(), messages, metadata));
langfuseTraceService.endTrace(traceId, Map.of("error", e.getMessage()));
throw e;
}
}
}실패한 호출도 트레이싱하는 게 중요합니다. 에러가 났을 때 Langfuse 대시보드에서 어떤 입력으로 어떤 에러가 났는지 바로 확인할 수 있으니까요. catch 블록에서 트레이스를 남기고 예외는 그대로 다시 던집니다.
실제 비즈니스 서비스에서 쓰기#
여기까지가 인프라 레이어였고, 이제 비즈니스 서비스에서 이걸 실제로 어떻게 호출하는지 봅니다.
PromptId — 프롬프트를 Enum으로 관리#
프롬프트 이름이나 fallback 텍스트를 서비스 코드에 문자열로 흩뿌려두면 관리가 안 됩니다. 도메인별로 Enum을 만들어서 프롬프트 메타데이터를 한 곳에 모읍니다.
public interface PromptId {
String promptName(); // Langfuse에 등록된 프롬프트 이름
String description(); // 문서화용 설명
default String fallbackPrompt() { return null; }
}도메인별로 이 인터페이스를 구현하는 Enum을 만듭니다. 예를 들어 텍스트 요약 기능이라면:
public enum SummaryPrompt implements PromptId {
DOCUMENT_SUMMARY(
"document_summary",
"문서를 요약하는 프롬프트",
"""
다음 문서를 읽고 핵심 내용을 3~5줄로 요약하세요.
문서:
{{document}}
응답은 반드시 다음 JSON 형식으로만 반환하세요:
{"summary": "요약 텍스트", "keywords": ["키워드1", "키워드2"]}
"""
),
FEEDBACK_ANALYSIS(
"feedback_analysis",
"사용자 피드백을 분석하여 감성과 핵심 이슈를 추출하는 프롬프트",
"""
다음 사용자 피드백을 분석하세요.
피드백:
{{feedback}}
응답은 반드시 다음 JSON 형식으로만 반환하세요:
{"sentiment": "positive/negative/neutral", "issues": ["이슈1", "이슈2"]}
"""
);
private final String promptName;
private final String description;
private final String fallbackPrompt;
// 생성자, getter 생략
@Override
public String promptName() { return promptName; }
@Override
public String description() { return description; }
@Override
public String fallbackPrompt() { return fallbackPrompt; }
}Enum에 fallback 프롬프트를 text block으로 직접 넣어두는 이유가 있습니다. Langfuse 서버가 죽었을 때 이 텍스트가 그대로 사용되기 때문에, 프롬프트 내용이 코드에도 남아있어야 합니다. Langfuse에 등록된 프롬프트와 100% 같을 필요는 없고, 최소한의 동작이 가능한 수준이면 됩니다.
fallback이 필요 없는 프롬프트도 있습니다. 예를 들어 AI 브리핑 같은 부가 기능은 Langfuse가 안 되면 "생성할 수 없습니다"라고 빈 결과를 반환하는 게 맞아서, fallback 프롬프트 없이 만듭니다.
public enum BriefingPrompt implements PromptId {
WEEKLY_BRIEFING(
"weekly_briefing",
"주간 데이터 기반 AI 브리핑 생성"
);
// fallbackPrompt()는 기본값 null → Langfuse 실패 시 빈 결과 반환
}서비스 코드에서 호출#
비즈니스 서비스에서는 PromptId Enum과 LLMService만 알면 됩니다. Langfuse 연동 디테일은 전혀 신경 쓸 필요가 없습니다.
@Service
@RequiredArgsConstructor
public class DocumentSummaryService {
private final LLMService llmService;
public SummaryResultDto summarize(String documentText) {
return llmService.chat(
LLMPromptRequest.of(
SummaryPrompt.DOCUMENT_SUMMARY.promptName(),
Map.of("document", documentText),
SummaryPrompt.DOCUMENT_SUMMARY.fallbackPrompt()
),
List.of(new LLMMessage.User(documentText)),
SummaryResultDto.class
);
}
}LLMPromptRequest.of()에 프롬프트 이름, 변수, fallback을 넘기면 끝입니다. 내부적으로는 Langfuse에서 프롬프트를 가져오고, Config에서 모델을 결정하고, 호출 결과를 트레이싱하는 것까지 전부 알아서 돌아갑니다. 서비스 코드 입장에서는 "이 프롬프트로, 이 변수를 넣고, 이 타입으로 응답 받아줘"만 말하면 됩니다.
변수가 여러 개이거나 조합이 복잡한 경우에는 빌더 패턴으로 좀 더 깔끔하게 쓸 수도 있습니다.
LLMPromptRequest request = PromptRequestBuilder
.from(SummaryPrompt.FEEDBACK_ANALYSIS)
.variable("feedback", userFeedbackText)
.variable("targetDate", "2026-03-01")
.build();
llmService.chat(request, messages, FeedbackResultDto.class);붙여놓고 나면#
여기까지 구현한 걸 한 번에 보면 흐름은 이렇습니다.
코드에서 직접 Langfuse를 의식하는 부분은 LLMServiceImpl 한 곳뿐이고, 나머지 비즈니스 로직은 LLMService 인터페이스만 주입받아서 씁니다. Langfuse가 활성화됐든 아니든, 호출하는 쪽 코드는 동일합니다.
다음 편#
이번 편에서는 Langfuse의 기본 통합, 그러니까 프롬프트 조회와 트레이싱, NoOp 패턴까지 묶어봤습니다. 그런데 이 상태로 바로 프로덕션에 올리기에는 걸리는 지점이 남아 있었습니다.
LLM 호출할 때마다 Langfuse API를 찌르면 latency가 추가됩니다. 같은 프롬프트를 반복 조회하는 건 낭비고요. 트래픽이 몰리면 같은 프롬프트를 동시에 여러 스레드가 가져오려는 Thundering Herd 문제도 발생합니다.
다음 편에서는 Redis 캐싱, Double-Checked Locking, 분산 락으로 이 문제들을 어떻게 눌렀는지 이어서 적었습니다.
참고 자료