EC2 프리티어에서 Spring Boot 모니터링 구축기 (Prometheus + Grafana)
왜 모니터링이 필요했나#
Dayner는 실제 카페에서 사용하는 운영 서비스입니다. AWS EC2 프리티어 위에 Spring Boot 서버를 올려서 운영하고 있었는데, 서비스 초기부터 모니터링 환경을 갖추고 싶었습니다.
이유는 단순했습니다. CloudWatch만으로는 Spring 내부 상태를 볼 수 없었거든요.
CloudWatch가 보여주는 건 EC2 인스턴스 레벨의 CPU, 네트워크 I/O 정도입니다. 정작 알고 싶었던 건 이런 것들이었습니다:
- JVM Heap 메모리가 지금 얼마나 차있는지
- 스레드가 몇 개 돌고 있는지, WAITING 상태는 몇 개인지
- GC가 얼마나 자주 일어나는지
- HikariCP 커넥션 풀이 고갈되고 있진 않은지
이건 애플리케이션 레벨 모니터링이 아니면 볼 수가 없습니다. 그래서 서비스 초기에 Prometheus + Grafana를 세팅해놓기로 했습니다.
나중에 이 결정이 Thread Starvation 장애를 디버깅할 때 결정적인 역할을 했습니다.
아키텍처#
프리티어 EC2 하나에 Spring Boot + Prometheus + Grafana를 다 올렸습니다. 별도 VPC나 별도 인스턴스를 쓰면 비용이 나가니까, 최소 비용이 목표였던 Dayner에서는 같은 인스턴스에서 모든 걸 돌렸습니다.
EC2 (프리티어 t2.micro / 1GB RAM)
├── Spring Boot (:8080)
│ └── Actuator + Micrometer → /actuator/prometheus
├── Prometheus (:9090)
│ └── 1분 간격으로 /actuator/prometheus scrape
└── Grafana (:3000)
└── Prometheus를 데이터소스로 대시보드 구성
1GB RAM에 세 개를 올리는 건 솔직히 빡빡하긴 했습니다. 나중에 스왑 메모리를 추가한 이유 중 하나이기도 합니다.
Spring Actuator + Micrometer 세팅#
Spring Boot에서 Prometheus가 수집할 메트릭을 노출하려면 Actuator와 Micrometer가 필요합니다. (Spring Boot Actuator, Micrometer Prometheus)
// build.gradle
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus'application.yml에서 Prometheus 엔드포인트를 활성화합니다.
management:
endpoints:
web:
exposure:
include: health, prometheus
metrics:
export:
prometheus:
enabled: true이렇게 하면 /actuator/prometheus에서 Prometheus 포맷의 메트릭이 노출됩니다. JVM heap, GC, 스레드, HikariCP 커넥션 풀 등이 기본으로 포함됩니다.
보안 측면에서 Actuator 엔드포인트를 외부에 완전히 노출하는 건 위험합니다. Dayner는 EC2 보안 그룹에서 Prometheus 포트(9090)와 Actuator 포트를 내부에서만 접근 가능하도록 제한해두었기 때문에 별도 인증은 추가하지 않았습니다.
Prometheus 수집 설정#
Prometheus의 prometheus.yml에서 Spring Boot 서버를 타겟으로 등록합니다. (Prometheus Configuration)
global:
scrape_interval: 60s
scrape_configs:
- job_name: 'dayner-spring'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['localhost:8080']수집 주기는 1분으로 설정했습니다. 프리티어 EC2의 리소스를 고려하면 15초나 30초는 부담이 될 수 있어서 1분이 적절했습니다.
오토스케일링과의 관계#
Dayner는 오토스케일링 그룹을 사용하고 있어서, 인스턴스가 교체되면 Prometheus도 함께 사라집니다. 사실 이 부분은 제대로 대응하지 못했습니다. static_configs로 localhost만 바라보고 있어서, 인스턴스가 교체되면 이전 메트릭 데이터는 날아갑니다.
제대로 하려면 EC2 service discovery를 쓰거나 Prometheus를 별도 인스턴스로 분리해야 하는데, 프리티어 제약 안에서는 타협한 부분입니다. 대신 Grafana 대시보드의 스냅샷 기능으로 중요한 시점의 상태는 별도로 저장해뒀습니다.
Grafana 대시보드#
Grafana에서 Prometheus를 데이터소스로 연결하고 대시보드를 구성했습니다. (Grafana - Prometheus Data Source)
기본 구성은 커뮤니티에서 인기 있는 Spring Boot 대시보드를 가져다 썼습니다. JVM 메모리, GC, 스레드 상태 등을 한눈에 보여주는 패널들이 잘 정리되어 있어서 처음 붙일 때 편했습니다.
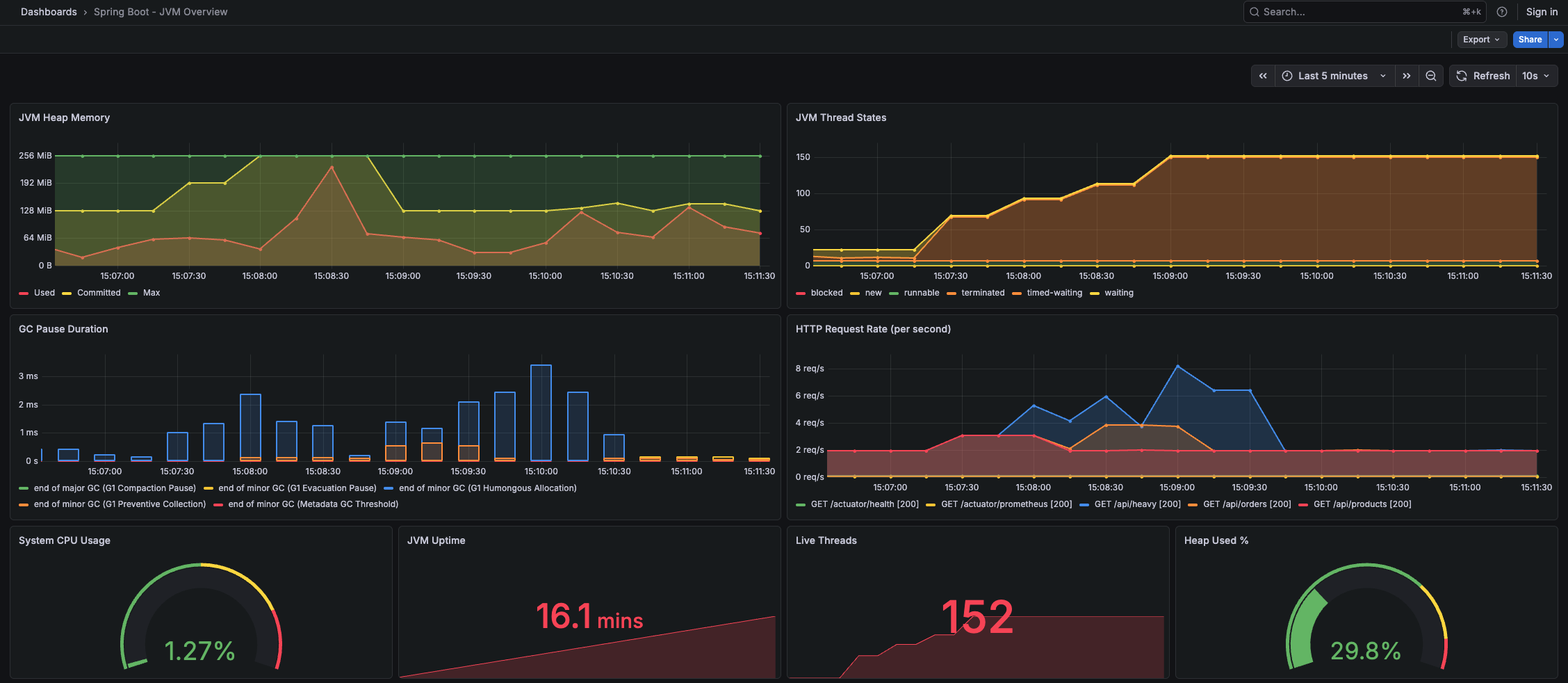
주로 본 메트릭들#
JVM Heap Memory
jvm_memory_used_bytes— 현재 사용 중인 힙 메모리jvm_memory_committed_bytes— JVM이 확보한 힙 메모리- 이 두 값의 차이가 좁아지면 GC 압박이 심해지고 있다는 신호
스레드 상태
jvm_threads_states_threads— RUNNABLE, WAITING, TIMED_WAITING, BLOCKED 별 스레드 수- Thread Starvation 장애 때 이 메트릭이 핵심이었다
GC
jvm_gc_pause_seconds— GC pause time- 균등한 간격으로 발생하면 정상, 갑자기 길어지면 메모리 이슈
커스텀 메트릭: 주문 API 트래킹#
커뮤니티 대시보드는 JVM 전반을 보여주지만, Dayner에 특화된 지표는 직접 만들어야 했습니다. 카페 특성상 주문이 들어오는 시간대가 정해져 있어서, 주문 API의 호출 수와 응답 시간을 별도로 트래킹했습니다.
Micrometer의 @Timed를 쓰면 메서드 단위로 호출 수, 응답 시간, 에러율이 자동으로 Prometheus 메트릭에 노출됩니다.
@RestController
@RequestMapping("/api/orders")
public class OrderController {
@Timed(value = "dayner.orders.create",
description = "주문 생성 API 응답 시간",
percentiles = {0.5, 0.95, 0.99})
@PostMapping
public OrderResponse createOrder(@RequestBody OrderRequest request) {
return orderService.create(request);
}
@Timed(value = "dayner.orders.list",
description = "주문 목록 조회 API 응답 시간")
@GetMapping
public List<OrderResponse> listOrders() {
return orderService.listToday();
}
}percentiles = {0.5, 0.95, 0.99}를 넣으면 중앙값, p95, p99 응답 시간이 각각 메트릭으로 나옵니다. p99가 갑자기 튀면 일부 사용자가 느린 응답을 받고 있다는 뜻입니다.
@Timed만으로 부족한 경우에는 커스텀 Counter나 Gauge를 직접 등록할 수도 있습니다.
@Component
public class OrderMetrics {
private final Counter orderSuccessCounter;
private final Counter orderFailCounter;
public OrderMetrics(MeterRegistry registry) {
this.orderSuccessCounter = Counter.builder("dayner.orders.success")
.description("성공한 주문 수")
.register(registry);
this.orderFailCounter = Counter.builder("dayner.orders.fail")
.description("실패한 주문 수")
.register(registry);
}
public void recordSuccess() { orderSuccessCounter.increment(); }
public void recordFail() { orderFailCounter.increment(); }
}Grafana 패널 구성#
커스텀 메트릭을 Grafana에서 시각화할 때 쓴 PromQL 쿼리들입니다.
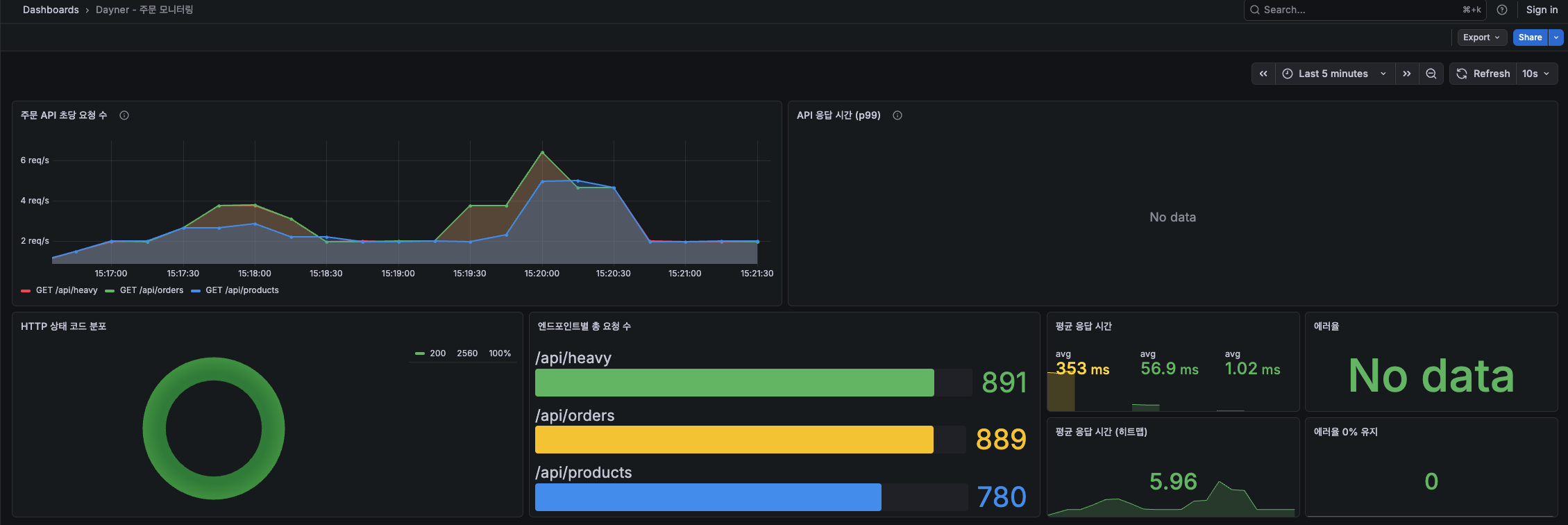
주문 API 초당 요청 수 (Rate)
rate(dayner_orders_create_seconds_count[1m])
1분 윈도우로 smoothing한 초당 요청 수입니다. 카페 오픈 시간(오전 8~9시)에 스파이크가 생기고, 점심 이후 줄어드는 패턴이 보였습니다.
주문 API p99 응답 시간
dayner_orders_create_seconds{quantile="0.99"}
p99가 1초를 넘기면 사용자 체감이 생기기 시작합니다. Dayner에서는 0.5초를 기준으로 잡았습니다.
에러율
rate(dayner_orders_fail_total[5m]) / rate(dayner_orders_create_seconds_count[5m])
성공/실패 비율. 이 값이 0이 아니면 뭔가 문제가 있다는 뜻이라, Grafana에서 임계값 0.01(1%)을 넘으면 패널이 빨간색으로 바뀌게 설정했습니다.
장애 대응에 도움이 된 순간#
이 모니터링 환경이 빛을 발한 건 Thread Starvation 장애가 발생했을 때입니다.
서버가 간헐적으로 죽는데 원인을 모르는 상황에서, Grafana 대시보드를 통해:
- Heap 영역은 안정적임을 확인 → 메모리 누수는 아님
- GC도 균등한 매그니튜드로 실행 중 → GC 문제도 아님
- 스레드 상태에서 이상 징후 발견 → Thread Starvation 의심
모니터링이 없었으면 그냥 EC2가 가끔 죽는다는 현상만 보고 원인 찾느라 한참 걸렸을 겁니다.
스레드 덤프 자동 생성#
CPU 사용량이 70%를 넘거나 요청이 5건 이상 쌓이는 경우를 CloudWatch에서 catch해서, 이벤트 발생 후 10분간 30초 간격으로 jstack을 활용해 스레드 덤프를 자동 생성하도록 구성했습니다.
이건 Prometheus가 아니라 CloudWatch 알람 + EC2 SSM Run Command로 구현한 건데, 무료 범위 내에서 가능했습니다. Prometheus의 AlertManager를 쓰면 더 세밀한 알림이 가능하지만, 프리티어 제약 안에서는 CloudWatch 알람이 비용 면에서 더 나았습니다.
프리티어에서의 비용#
모니터링 구성에 들어간 추가 비용은 0원입니다.
- EC2: 프리티어 t2.micro (기존에 쓰던 것)
- Prometheus + Grafana: 오픈소스, 라이선스 비용 없음
- EBS: 기본 8GB에서 추가한 12GB도 프리티어 30GB 한도 내
- CloudWatch 알람: 기본 무료 티어 내
유일한 비용은 나중에 스왑 메모리를 추가하면서 EBS 볼륨을 20GB로 키운 것인데, 이것도 프리티어 범위였습니다.
EC2 프리티어 제약 안에서도 Prometheus + Grafana로 꽤 쓸 만한 모니터링 환경이 나왔습니다. 물론 완벽하진 않습니다. 오토스케일링 대응은 약하고, 메트릭 데이터 영속성도 강하지 않습니다.
그래도 있고 없고의 차이는 생각보다 훨씬 컸습니다. Thread Starvation을 잡을 수 있었던 것도 결국 미리 메트릭을 보고 있었기 때문입니다.
직접 장애를 한 번 겪고 나니, 모니터링 없이 운영하는 건 이제 좀 무섭게 느껴졌습니다.